Dados para Data Lineage
Para a execução deste serviço, são consideradas duas fases distintas. Uma correspondente a interpretação dos Programas Cobol escritos com atividades e funções Hogan e fazer a sua conversão para estruturas convencionais de Programas Cobol, e uma outra subsequente a de Preparação dos Dados para a Geração do Data Lineage.
Fase 1
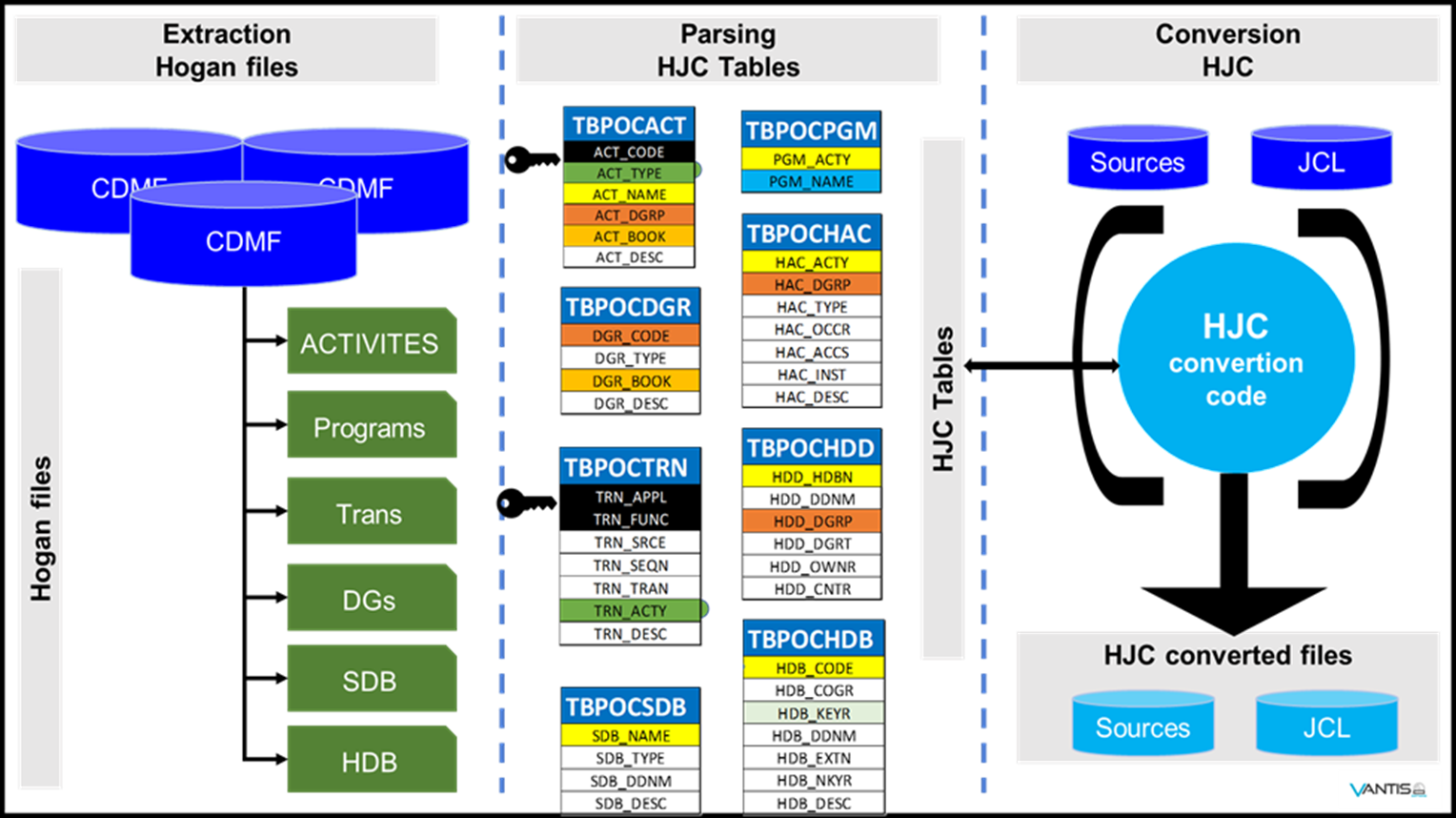
Interpretação dos Programas Cobol escritos com atividades e funções Hogan e fazer a sua conversão para estruturas convencionais de Programas Cobol.
A partir de processos automáticos – próprios – a conversão é iniciada pela leitura do JCL, e a partir dele, são identificados os objetos para serem convertidos, nomeadamente Programas, Subprogramas, Copybooks e Dclgen.
Fase 2
Programas Assembler
- Inventariação: Volumetria dos programas Assembler que fazem parte do “Processo de Conversão” dos programas COBOL HOGAN para estruturas convencionais de programas COBOL.
- Análise dos programas
- A identificação dos programas Assembler a serem analisados será automática e executada pelo processo já desenvolvido.
- Fazer a leitura de todos os programas e descrever os seguintes pontos:
- Tipo;
- PGM;
- Input área;
- Output área;
- Impacto Lineage;
- Data;
- Observações.
Preparação dos Dados para Geração do Data Lineage
- Capacitar o processo de:
- Regras de Inclusão e exclusão: incluir na seleção inicial de cadeias IWS a serem processadas a capacidade de excluir e ou incluir JCL’s por mecanismos de filtros sobre a sua nomenclatrura.
- Gerar deltas de atualizações: incluir ao processo a capacidade em caso de reprocessamento de uma cadeia identificar e selecionar apenas os objetos que sofreram alterações.
- Será necessário manter dados de objetos e versões tratadas;
- A eliminação de objetos, se limita a identificar os objetos eliminados.
- Tratamento das informações globais de JCL’s:
- Através do Parsing das JCL’s, criar um estrutura de dados padronizada que permita a fácil identificação dos objetos necessários ao Lineage, como processamento SAS (SCRIPS, MACROS), Utilitários de sistemas (SORT, IDCAMS, IEBGENER, etc..), utilitários DB2 (SYSIN, SYSTSIN), C:D: (MACROS, processos, etc…) entre outros.
- Integrar esta informação ao processo de modo a capacitar o processo selecionar de forma dinâmica os objetos que devem ser selecionados para a composição do Lineage.